
Con il termine “Trailing Slash” si indica la barra (slash) finale dell’URL. A seconda di dov’è posizionato, questo elemento può avere delle conseguenze sull’URL, oppure può essere ignorato dai browser e dai motori di ricerca.
Il Trailing Slash alla fine dell’URL serviva inizialmente a separare una directory (https://sistrix.it/chiedi-a-sistrix/) da un file (https://sistrix.it/chiedi-a-sistrix.html).
Poiché ormai gli URL sono in gran parte creati virtualmente e non hanno più un riferimento diretto con il file system del server, lo scopo del Trailing Slash è cambiato.
A seconda della sua posizione, il Trailing Slash può avere degli effetti sull’URL che lo contiene e causare problemi di contenuti duplicati.
Anche John Müller di Google ha affrontato questo argomento, spiegando quando il Trailing Slash è rilevante:
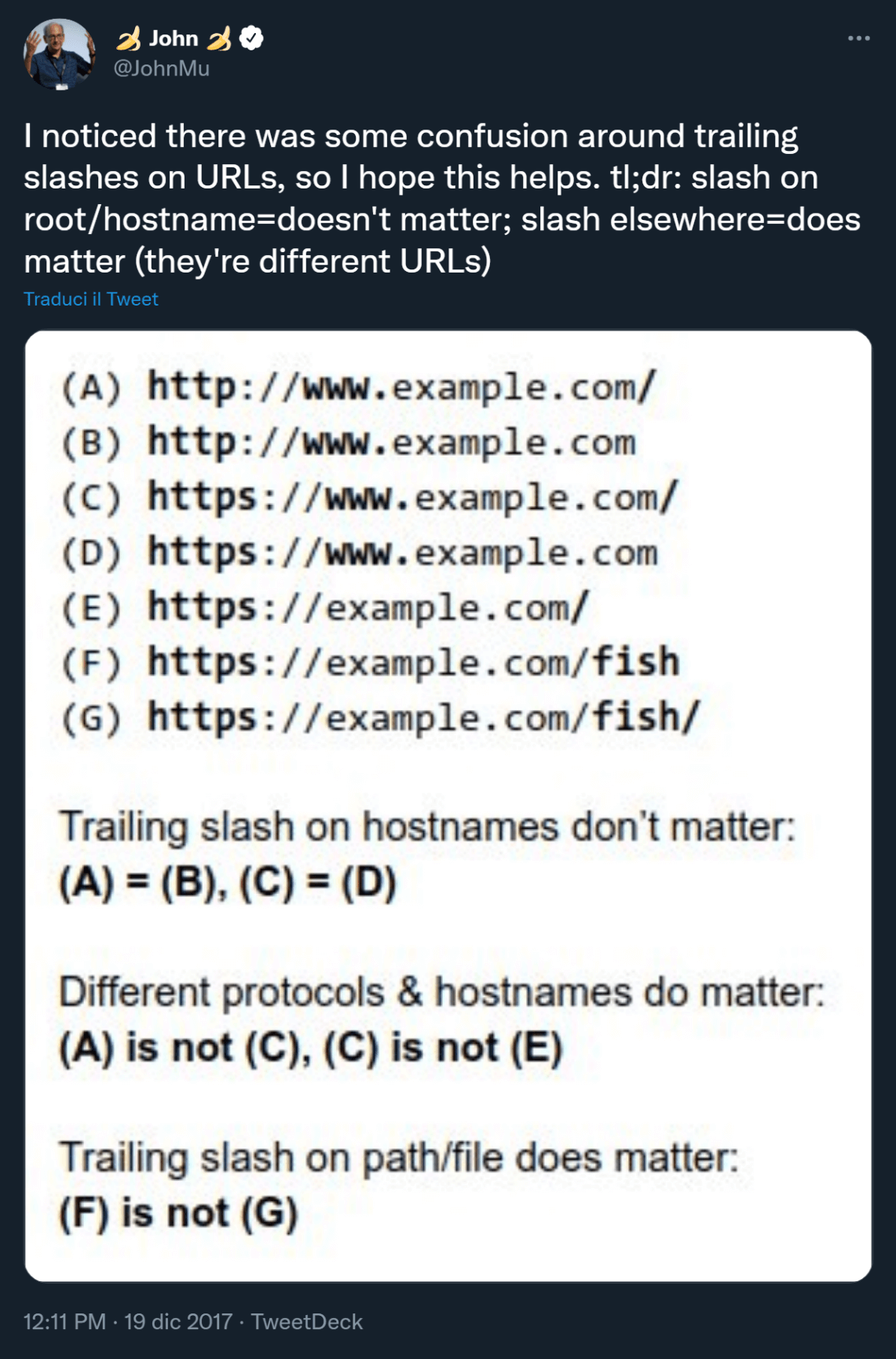
Alla fine di un sottodominio l’utilizzo del Trailing Slash non fa alcuna differenza: un browser (e Google), ad esempio, trattano https://sistrix.it nello stesso modo di https://sistrix.it/.
Diverso il caso delle directory: prendiamo ad esempio “Chiedi a sistrix”: per il browser (e quindi anche per gli utenti e Googlebot) fa differenza se la pagina si trova in https://sistrix.it/chiedi-a-sistrix o in https://sistrix.it/chiedi-a-sistrix/.
Si tratta infatti di due URL differenti, che possono contenere (eventualmente) proprie risorse e rispondere al sistema (ad esempio ad un browser) in modo diverso.
Questo significa che, lato SEO, se il proprio sistema non distingue gli URL con e senza Trailing Slash, si può incorrere velocemente in problemi di contenuti duplicati, in quanto entrambe le versioni potrebbero mostrare lo stesso contenuto e riportare un codice di stato 200.