
Se desideri impedire a Google di scansionare totalmente o parzialmente il tuo dominio, puoi utilizzare il cosiddetto robots.txt per indicare al crawler quali contenuti scansionare e quali escludere.
Nota: per bloccare specifici URL puoi utilizzare il Meta Tag Robots. Ricorda inoltre che, in alcuni casi, gli URL potrebbero venire comunque indicizzati anche se l’accesso a Google è stato vietato tramite robots.txt.
Bloccare GoogleBot tramite robots.txt
Il robots.txt è un semplice file di testo chiamato “robots” che deve essere inserito nella directory principale (root) del sito per fare in modo che sia letto dai motori di ricerca.
Il robots.txt deve essere utilizzato come segue:
http://www.miodominio.it/robots.txtIl contenuto del robots.txt
Usa le istruzioni seguenti all’interno del robots.txt per vietare a GoogleBot la scansione dell’intero sito:
User-Agent: Googlebot
Disallow: /Se invece vuoi solo limitare l’accesso di GoogleBot a determinate directory o file, imposta il robots.txt nel modo seguente:
User-Agent: Googlebot
Disallow: /questa-directory/
Disallow: /questo-file.pdfAlcuni URL potrebbero venire ancora indicizzati
Gli esempi mostrati nei punti precedenti sono pensati solo per GoogleBot: i crawler di altri motori di ricerca (come Bing) non saranno però bloccati.
Ricorda inoltre che vietare l’accesso al crawler non garantisce che il sito o l’URL non venga mostrato nelle pagine dei risultati (o SERP). Per saperne di più su questo argomento puoi leggere l’articolo “Perché un URL bloccato tramite robots.txt compare comunque nei risultati di ricerca?“.
Bloccare i crawler usando WordPress
Su WordPress è disponibile una funzione per impostare il Meta Tag Robots di singole pagine come noindex.
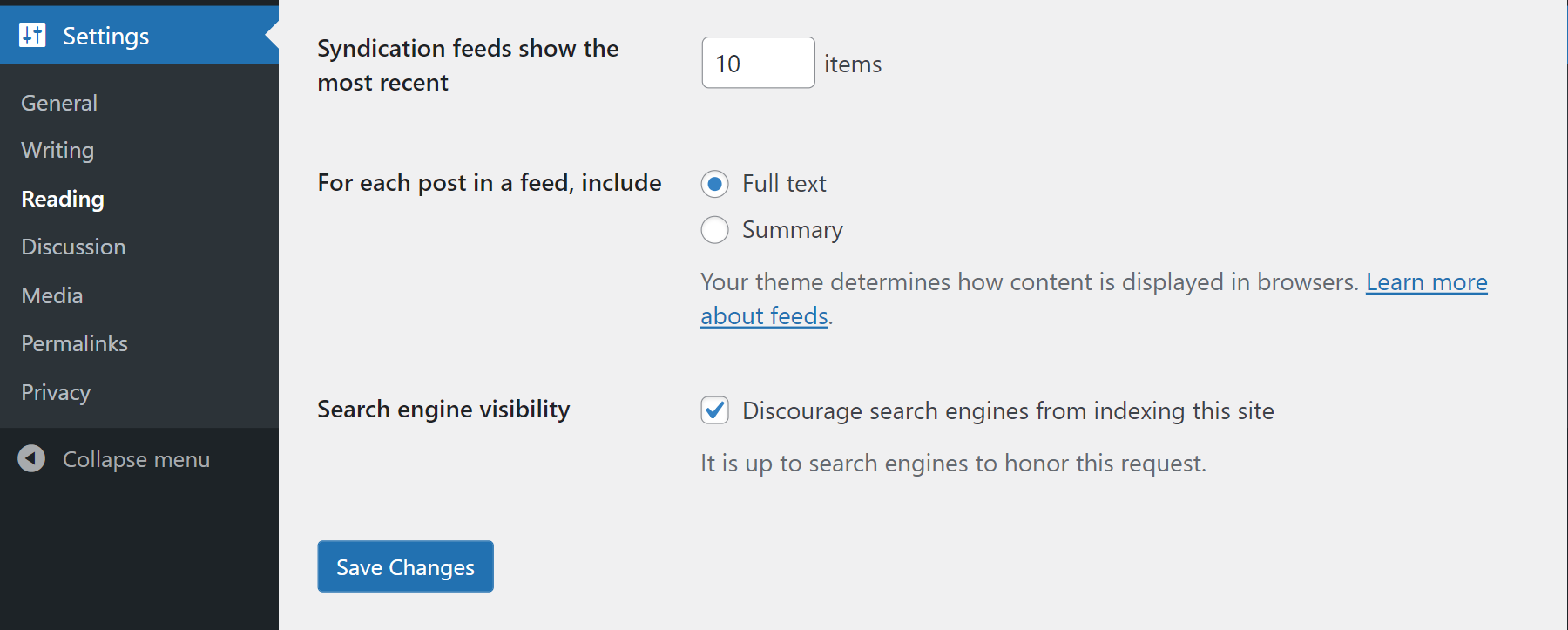
Se sei amministratore puoi infatti aprire le impostazioni e spuntare l’opzione “Scoraggia l’indicizzazione del sito da parte dei motori di ricerca”.