
Che cosa hanno in comune una pagina dei risultati di Google e uno scaffale del supermercato? 1. Hanno uno scopo preciso; 2. Lo spazio disponibile è limitato (problema).
- Perché Google non mostra semplicemente più di 10 risultati?
- Problema matematico: ottimizzare lo spazio degli scaffali del supermercato
- Soluzione del problema matematico
- Come convertire questa ottimizzazione dello spazio su scaffale per Google?
- Google non può classificare ogni risultato per ciascuna richiesta di ricerca
- I segnali di link sono estremamente importanti, ma hanno anche dei limiti
- Esiste un numero limitato di segnali disponibili per le pagine individuali
- Google classifica la qualità dell'intero dominio
- Google valuta anche il comportamento degli utenti
- Quali sono i dati analizzati da Google per valutare il comportamento degli utenti?
- I limiti dei dati del CTR
- Come fa Google a valutare i dati del CTR per l'intero dominio?
- La visibilità di un dominio oscilla con i trend
- Come si traduce tutto questo nella vita reale?
- 9 consigli per ottimizzare la rivendicazione del vincolo nella vita reale

In entrambi i casi, il punto numero 2 è il fattore delimitante per la performance dell’intero sistema. Il supermercato potrebbe infatti guadagnare di più con maggiore spazio sugli scaffali, perché offrirebbe una grande varietà di prodotti e soddisferebbe ulteriormente i bisogni d’acquisto. Allo stesso modo, Google potrebbe soddisfare maggiori richieste di ricerca se la prima pagina dei risultati di ricerca potesse ospitare più di 10 risultati organici (Searcher Satisfaction, chiamato anche Needs-Met-Rating nelle Linee Guida sulla Qualità di Google).
Sia Google, che il supermercato devono affrontare il problema di selezionare le offerte perfette per il proprio spazio limitato. Se però la procedura usuale seguita dal supermercato è ben conosciuta e fa parte delle nozioni base dell’economia aziendale, tutto ciò che abbiamo, quando si parla di Google, è un groviglio di perplessità e supposizioni. Alla luce di questo fatto, quella di studiare le scelte di selezione compiute dal supermercato potrebbe rivelarsi un’ottima idea. Forse, così facendo, potremo imparare come Google sceglie i propri risultati.
Perché Google non mostra semplicemente più di 10 risultati?
A prima vista, sembra che la via più semplice per migliorare la soddisfazione degli utenti sia, per Google, quella di visualizzare più di 10 risultati organici per pagina (SERP). Google aveva consultato i suoi utenti riguardo a questo argomento e questi avevano espresso il desiderio di avere più risultati: più ce n’è, meglio è, dopo tutto.
Secondo l’allora vicepresidente di Google, Marissa Mayer, la società ha poi condotto un test con 30 risultati per SERP. La versione con 30 risultati ha mostrato un calo del 20% nel traffico e nei profitti rispetto alla versione con 10 risultati. Com’è possibile?
Google ha bisogno di 0,4 secondi per creare e trasmettere una SERP da 10 risultati. La pagina con 30 risultati, d’altro canto, ha impiegato 0,9 secondi per caricarsi. Questa differenza di 0,5 secondi ha distrutto la soddisfazione degli utenti e portato a un nuovo problema che è costato il 20% del traffico. Attualmente, grazie a questo esperimento, Google mostra solo 10 risultati organici.
Il supermercato ha essenzialmente lo stesso problema. In teoria, la direzione del negozio potrebbe semplicemente aggiungere altri scaffali. Una misura del genere, tuttavia, restringerebbe i corridoi dove transitano i clienti e avrebbe un forte impatto negativo sull’intera esperienza d’acquisto. Ciò significa che la fornitura di un supermercato è limitata a una determinata area di pavimento.
Problema matematico: ottimizzare lo spazio degli scaffali del supermercato
Ora che abbiamo identificato il vincolo, possiamo dare un’occhiata a un semplice esempio. Supponiamo di avere, in un supermercato, uno scaffale dedicato a riviste e quotidiani. Lo scaffale si compone di 10 file che possono essere sfruttate per la merce. Il gestore del supermercato ha a disposizione i seguenti dati.
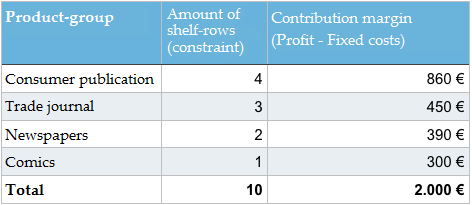
Nota: Vorrei scusarmi con i lettori per l’uso del termine economista “margine di contribuzione”, invece del termine colloquiale “profitto”. Non posso farne a meno. Spiegazione: Profitto = margine di contribuzione – costi fissi (affitto, costi del personale ecc.).
Come potrebbe il gestore del negozio disporre l’assortimento di riviste e quotidiani per massimizzare il margine di contribuzione? Dovrebbe apportare modifiche alla merce a disposizione? Quale soluzione suggeriresti?
Soluzione del problema matematico
La soluzione è molto semplice, se hai assimilato le basi dell’ottimizzazione del problema: l’intero sistema deve essere perfezionato per massimizzare al meglio il vincolo dello spazio disponibile sullo scaffale.
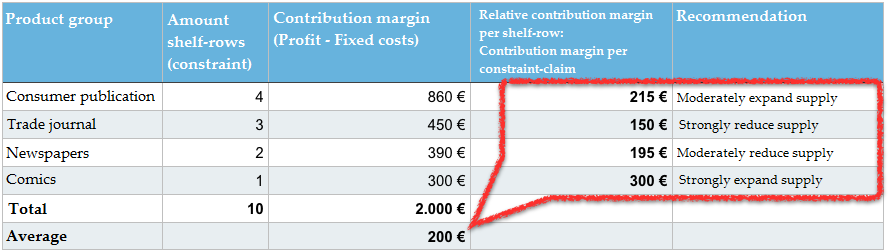
Il margine di contribuzione per gruppo di prodotti deve essere diviso per il numero delle file occupate degli scaffali. Il risultato è il margine di contribuzione relativo per gruppo di prodotti. L’assortimento dei gruppi di prodotti con un margine di contribuzione relativo >200 € viene espanso e quello con un margine relativo <200 viene ridotto
L’indicatore cruciale, qui, non è il margine di contribuzione per gruppo di prodotti della tabella 1 (pubblicazioni di consumo, riviste specializzate ecc.). Al fine di ottimizzare lo scaffale, abbiamo bisogno di un margine di contribuzione per vincolo (margine di contribuzione relativo per fila dello scaffale). Di conseguenza, non ci serve il margine di contribuzione totale di tutti i gruppi di prodotti, ma vogliamo sapere quanto margine di contribuzione siamo stati in grado di generare tramite lo spazio su scaffale già in uso. A tal fine, dividiamo il margine di contribuzione per gruppo di prodotti per il numero delle file occupate sullo scaffale, ottenendo così un margine di contribuzione relativo. Conosciamo questo principio grazie alle nostre valutazioni di marketing online, durante le quali lavoriamo con indicatori come il Click-Through-Rate (CTR) e consideriamo un certo numero di clic in relazione alla rivendicazione del vincolo (impression).
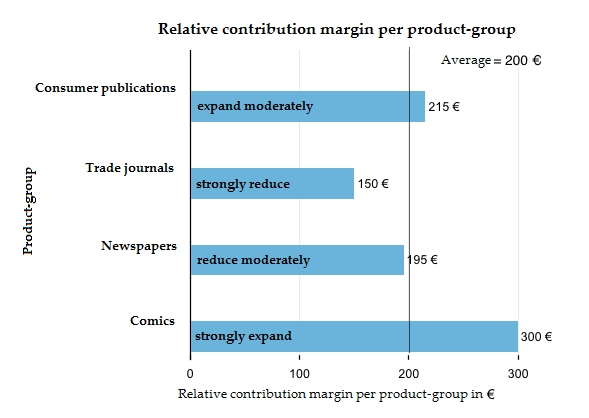
In media, 10 file di scaffale generano un margine di contribuzione di 200€ (2.000 € MC: 10 file). Le riviste specializzate ricavano soltanto 150€ per fila di scaffale. Questo fa di loro il gruppo di prodotti meno produttivo: sebbene siano quello con il secondo più alto margine di contribuzione, se non contiamo le pubblicazioni di consumo con 450€, occupano tre file intere e, di conseguenza, il 30% del nostro vincolo. Il tutto contribuendo soltanto per il 22,5% al margine di contribuzione. Potremmo certamente sfruttare questa sezione di spazio su scaffale più efficacemente.
Le riviste a fumetti generano soltanto un margine di contribuzione generale di 300€, ma occupano anche soltanto una fila dello scaffale. Per questa ragione, sono il gruppo di prodotti più redditizio con un margine di contribuzione relativo di 300€.
Possiamo scegliere facilmente quali aspetti ottimizzare. Dovremmo restringere tutti i gruppi di prodotti con un margine di contribuzione relativo minore rispetto alla media (< 200€) e, invece, riempire il loro spazio con quei gruppi di prodotti che hanno raggiunto un margine di contribuzione relativo maggiore rispetto alla media (> 200€).
Nel nostro esempio, il gestore del supermercato farebbe bene a dedicare meno spazio alle riviste specializzate e ai quotidiani, per provare a sfruttare il nuovo spazio libero con pubblicazioni di consumo e riviste a fumetti. Potrebbe rivelarsi redditizia l’introduzione di un nuovo gruppo di prodotti, come i libri tascabili, per esempio. L’obiettivo a lungo termine è quello di aumentare il margine di contribuzione medio per fila di scaffale.
Non esiste una soluzione esatta a questo problema, poiché non si conosce il beneficio marginale dei gruppi di prodotti. Il gestore non sa se espandere la sezione dei fumetti del 10, del 50 o del 100%. Sa soltanto la direzione da prendere nell’apportare le modifiche. Non ha altra via che quella di sperimentare e sperimentare per giungere, infine, alla soluzione ottimale. Una volta modificati i gruppi di prodotti a disposizione e il loro relativo spazio su scaffale, comincia un nuovo turno di prove.
Nella vita reale, il processo che porta a queste decisioni è molto più complesso, perché si hanno a disposizione molti più dati, opzioni e informazioni, per cui siamo consapevoli che l’esempio è molto semplificato.
Come convertire questa ottimizzazione dello spazio su scaffale per Google?
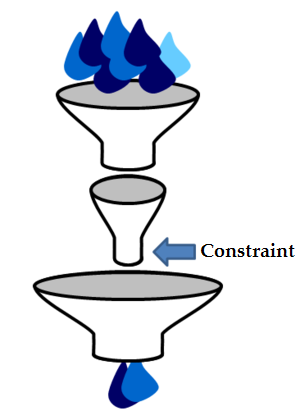
Il principio dell’ottimizzazione del vincolo, anche chiamato Theory of Constraints è un metodo pratico, di successo e ben conosciuto. Non viene usato soltanto dai commercianti al dettaglio al fine di valutare come utilizzare al meglio le aree di vendita disponibili, ma da tutti i ruoli di gestione aziendale (produzione, marketing, gestione del processo di produzione, finanza, controllo, gestione dei progetti ecc.).
L’immagine del modello a imbuto, qui a destra, serve per illustrare il teorema principale del Theory of Constraints: “In ogni catena di valori, è presente un unico sistema che determina le prestazioni totali – un vincolo determinato”.
Non sarebbe una sorpresa se Google decidesse di scoprire di nuovo l’acqua calda e applicare questo principio base al sistema che sceglie i risultati della sua ricerca. Ci sono alcuni punti a favore di questa teoria. Prima di poterci addentrare nel loro dettaglio, però, dobbiamo fare una deviazione e dare un’occhiata ad alcune ulteriori informazioni sul funzionamento della ricerca e dei ranking di Google.
Google non può classificare ogni risultato per ciascuna richiesta di ricerca
John Wiley, Lead Designer di Google Search, ha detto, nel 2013, che circa il 15% di tutte le richieste di ricerca giornaliere è inedito e non è mai stato richiesto prima su Google. Questo tasso corrisponde a circa 500 milioni di richieste di ricerca giornaliere. Per queste ricerche, Google non ha dati storici i cui risultati siano già stati definiti utili dagli utenti e soddisfino al meglio l’obiettivo della Searcher Satisfaction dell’utenza.
Tenteremo ora di fare una stima del numero di tali query di ricerca (cioè quelle chieste così raramente che non rientrano nel bacino di dati attuali di Google), con l’obiettivo di esaminare i risultati individuali. Non sorprenderebbe se questa quantità si attestasse attorno al 30-60% di tutte le query di ricerca.
Sebbene Google, tramite un’analisi OnPage, sia in grado di determinare se un risultato potrebbe essere rilevante per una query specifica di ricerca, non può valutare se un risultato soddisferà davvero l’utente. Per questa ragione, Google è obbligato a valutare altri segnali al fine di giungere a una previsione attendibile della qualità del risultato.
I segnali di link sono estremamente importanti, ma hanno anche dei limiti
Una volta valutati tutti i documenti che potrebbero rivelarsi rilevanti per una specifica query di ricerca, Google utilizzerà un altro dei suoi principi fondamentali: l’algoritmo PageRank. Si tratta di una procedura atta a valutare il numero dei documenti collegati dalla struttura dei link. Chiunque se ne intenda un minimo di SEO sa quanto i link sono importanti per i ranking di Google.
L’algoritmo PageRank funziona estremamente bene e ha fatto di Google il leader nel mercato dei motori di ricerca in poco tempo. Anche questo concetto, tuttavia, ha dei limiti.
Esiste un numero limitato di segnali disponibili per le pagine individuali
Google conosce più di 60 trilioni di pagine individuali. La grande maggioranza di questi documenti (URL) del World Wide Web non contiene link da siti esterni. Un dominio come eBay.de ha, attualmente, più di 30 milioni di URLs diversi all’interno dell’indice di Google. È estremamente probabile che solo una frazione di questi URLs contenga dei link esterni, in special modo se si considera che molti URLs diventano obsoleti allo scadere dell’asta. Lo stesso si applica per la maggior parte degli altri siti web.
Al fine di ottenere i dati dei link di ogni singolo URL, Google deve impegnarsi su larga scala per poter tenere in considerazione anche i link interni di un dominio. Il problema sta nel fatto che questi link sono affidabili sono fino a una certa misura, poiché sono controllati integralmente dagli operatori del sito web.
Allo stesso modo, anche i link esterni sono affidabili fino a una certa misura, perché anche loro, negli anni, sono stati manipolati con la compravendita.
Google classifica la qualità dell’intero dominio
Google è in grado di mitigare in parte il problema dell’insufficienza di dati dei singoli URL determinando la qualità del dominio corrispondente. Sfruttando la somma di tutti i segnali del dominio, inclusi tutti gli URL, Google viene in possesso di dati molto più flessibili per la valutazione della fonte specifica.

È perciò normale che Google parli di “sito (web) e qualità della pagina” durante la spiegazione del funzionamento dei suoi ranking.
Nei circoli SEO, quando ci si riferisce alla classificazione di Google nei riguardi di un intero dominio, si parla di Domain Trust o di Domain Authority (valutando il dominio in base ad argomenti specifici, come “salute” o “sport”).
Il nostro gestore di supermercato ha, essenzialmente, problemi simili. Quando si tratta di decidere l’assortimento dei prodotti, è semplicemente impossibile testare e valutare ogni numero di ciascuna singola rivista. Senza contare che, perfino da un numero al successivo, potrebbe esserci un cambio di qualità all’interno dello stesso prodotto. Il manager del supermercato deve affidarsi a una semplificazione di queste strutture complesse e raggruppare singoli numeri in gruppi di prodotti, come le pubblicazioni di consumo e le riviste specializzate. Questi gruppi di prodotti possono poi essere sottoposti ad analisi e confrontati l’un l’altro.
Google valuta anche il comportamento degli utenti
Si sa che, nei circoli SEO, Google non valuta solo i link, ma compie il passo successivo e analizza anche il comportamento dei consumatori. Utilizzando i dati dei link, è possibile ottenere un primo set di risultati più affidabili e rilevanti per le prime 10 posizioni.
Google può giungere a dei risultati di ricerca molto migliori analizzando il modo in cui gli utenti interagiscono con essi, cosa che potrebbe richiedere un riordino delle SERP.
Non sarebbe logico né conveniente tenere permanentemente lo stesso risultato in prima posizione quando gli utenti mostrano continuamente di preferire i risultati dalla posizione 2 alla 10. Sarebbe altrettanto illogico tenere permanentemente un risultato all’interno delle prime 10 posizioni se gli utenti interagiscono con esso molto raramente. Senza contare che, quando si parla di eventi attuali o dei cosiddetti “Temi caldi”, i link che crescono storicamente nel corso degli anni sono totalmente inutili. Quando i posizionamenti vengono riordinati, si parla di reranking, per il quale Google ha presentato una serie di specifiche di brevetto, dove, in caso di interesse, si possono trovare più dettagli.
I segnali degli utenti possono tenere in considerazione fattori come la qualità dei contenuti, del sito web e le preferenze degli utenti (i brand, per esempio). In caso di qualsiasi dubbio, puoi stare sicuro che il “voto” dell’utente verrà considerato più prezioso e affidabile di semplici dati di link. Allo stesso tempo, questi ultimi sono importanti per la possibilità del sito di essere fra quelli scelti al momento del voto.
Quali sono i dati analizzati da Google per valutare il comportamento degli utenti?
Non sappiamo quali dati del comportamento degli utenti siano specificatamente valutati da Google per i suoi posizionamenti o per il reranking, così come Google definisca esattamente la Searcher Satisfaction e classifichi i risultati individuali in base al comportamento degli utenti. Si può immaginare che utilizzi delle metriche come il CTR, i dati di clickstream, il time-on-site e il tasso return-to-SERP, per nominarne alcuni. Tutte queste metriche si originerebbero dal CTR.
Un’altra possibile fonte di dati ai fini della valutazione potrebbe essere il browser di Google Chrome, che conserva dati di praticamente qualsiasi dominio. Meno probabile è l’utilizzo dei dati di Google Analytics, perché questi sono disponibili solo per quei domini che lo utilizzano, quindi circa il 10% di tutti i domini, secondo i dati di buildwith.com. Questa percentuale, in verità, potrebbe rivelarsi maggiore per i siti web influenti e ben conosciuti.
Dall’altro lato, l’uso dei dati di Analytics minerebbe la credibilità di Google, perché l’azienda ha sempre dichiarato pubblicamente di non utilizzarli per i propri ranking. Il browser Chrome ha attualmente una quota del mercato mondiale del 40%, secondo i dati provenienti da StatCounter. Questo dovrebbe permettere a Google di ottenere dati utilizzabili per qualsiasi sito web del mondo. Quando si tratta di decidersi su una fonte di dati, Chrome è un’alternativa molto più utile di Analytics.
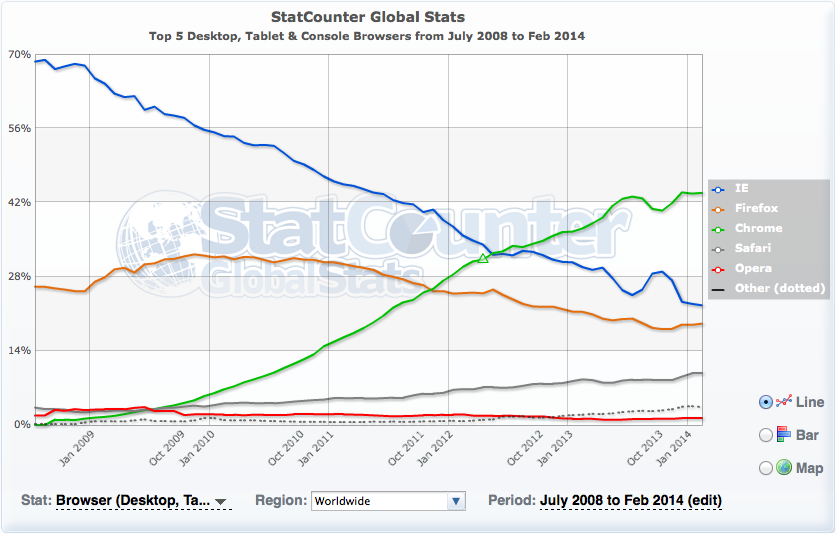
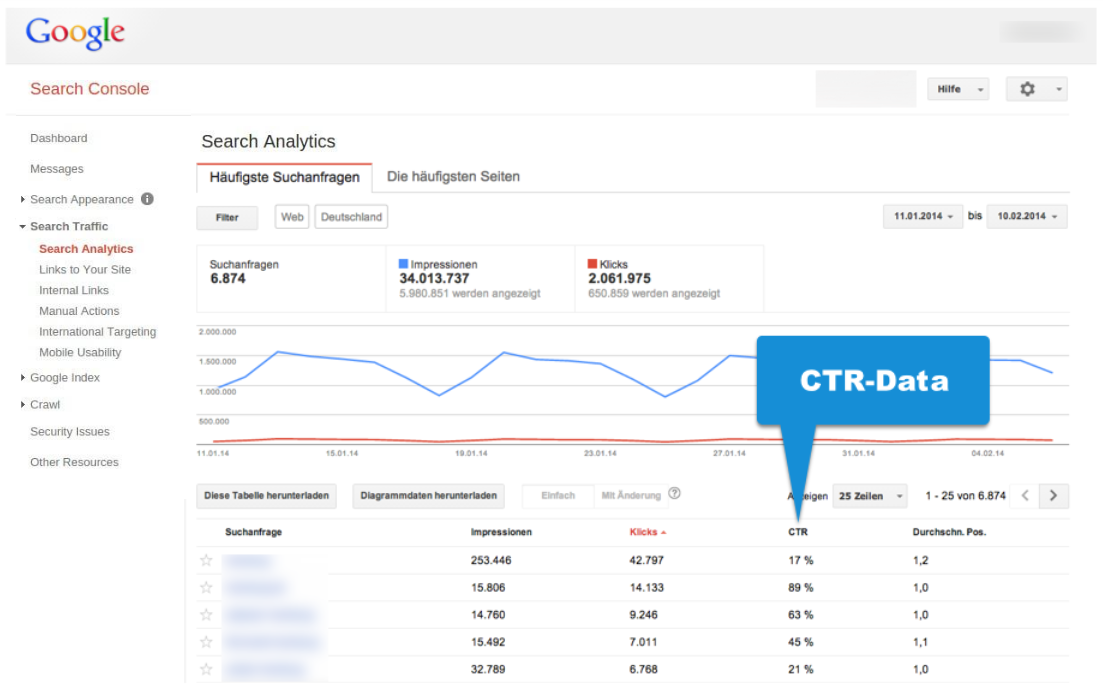
In aggiunta, Google ha ovviamente accesso diretto ai dati provenienti da Google Search. Siamo assolutamente certi che questi dati vengono monitorati e analizzati, perché Google mostra il CTR delle query di ricerca individuali e degli URLs all’interno di Google Search Console.
Diamo un’occhiata a questo esempio, in cui diremo, per ragioni di semplicità, che Google stima la “quota di soddisfazione” grazie al CTR. In realtà, questa valutazione sarà molto più complessa e pianificata.
Nel nostro esempio semplificato, il CTR sarebbe l’equivalente di Google-Search, il margine di contribuzione relativo nel nostro esempio del supermercato. Il CTR prende già in considerazione la rivendicazione del vincolo. Il valore del numero dei click viene considerato in relazione alle impressioni (vincolo).
I limiti dei dati del CTR
Come abbiamo dichiarato in precedenza, non esiste alcun dato delle pagine individuali disponibile per la maggioranza dei siti web. Questo è valido sia per i dati di link, sia per i dati del CTR.
Possiamo vederlo chiaramente all’interno di Google Search Console, se diamo un’occhiata a questi ultimi. Prima o poi arriveremo a un punto in cui Google mostrerà soltanto i valori dei click minori di 10 nella lista delle keyword e dei singoli URLs.
I dati che vedi nell’esempio di cui sopra, che provengono da un grosso dominio analizzato con più di 34 milioni di impressioni SERP e più di due milioni di click al mese, mostrano un valore minore di 10 click al mese per circa il 50% delle query di ricerca. Dobbiamo tenere a mente che Google ci mostrerà soltanto le richieste di ricerca più popolari. In questo caso, ci sono stati mostrati solo 6 dei 34 milioni di impressioni SERP, circa il 18%. Google non ha dati affidabili sui risultati di un dominio individuale per la maggior parte delle query di ricerca.
Tutto sommato, risulta piuttosto chiaro che i dati del CTR possono soltanto offrire informazioni fino a un certo grado di attualità per query di ricerca popolari, indipendentemente dai valori esatti del CTR. Questo significa che i dati del CTR, proprio come i dati di link, finiranno per scontrarsi contro un muro per un gran numero di query di ricerca.
Come fa Google a valutare i dati del CTR per l’intero dominio?
Sarebbe sensato che Google considerasse i dati del CTR per l’intero dominio (o, piuttosto, una definizione molto più studiata, ma sconosciuta per noi, di “Searcher Satisfaction”). Questo indicatore potrebbe, allora, diventare parte della metrica onnicomprensiva “Domain Trust”.
L’idea alla base è piuttosto semplice: se l’intero dominio genera un grado di “Searcher Satisfaction” maggiore della media, allora è possibile fare in modo che la Searcher Satisfaction continui a crescere in tutte le ricerche di Google, mettendo in vista i risultati rilevanti provenienti da quel dominio in un numero maggiore di query di ricerca.
La vera ragione per cui gli utenti possono trovare certi risultati da domini specifici più soddisfacenti di altri (da domini con un grado simile di pertinenza) può essere molteplice. Il nome del dominio, le preferenze di brand, il tempo di caricamento, la qualità dei contenuti, lo stile del linguaggio, la fruibilità, l’aggressività degli annunci pubblicitari, la qualità dell’ottimizzazione degli snippet e l’affidabilità percepita sono solo alcuni dei criteri che possono giocare un ruolo e che vengono analizzati attraverso le interazioni coscienti o inconsapevoli che gli utenti hanno con i risultati.
Se seguiamo questa corrente di pensiero, allora dovrebbe essere nello spirito di questa “teoria dei vincoli” permettere a questi domini con un CTR più alto della media di avere più visibilità (impressioni SERP) all’interno delle SERP. Viceversa, le impressioni SERP di un dominio con dati del CTR più bassi della media verrebbero ridotte fino al raggiungimento di una quota media.
Questa strategia sarebbe adatta per aumentare la Searcher Satisfaction in generale, allo stesso modo in cui il gestore del supermercato del nostro esempio può aumentare il margine di contribuzione del suo scaffale espandendo la quota di gruppi di prodotti con un reddito nella norma.
La visibilità di un dominio oscilla con i trend
La visibilità di un dominio, generalmente, non traccia una linea retta, ma è soggetta a costanti sbalzi positivi e negativi. Per questa ragione, l’Indice di Visibilità mostrerà una serie di picchi e depressioni, la cui direzione indicherà il tipo di trend. Parleremo di un trend al rialzo nel caso in cui l’altezza dei picchi superi quella delle depressioni, mentre parleremo di trend al ribasso se vediamo una serie di picchi più bassi delle valli. Se vediamo una serie di picchi e valli aventi all’incirca la stessa altezza, parliamo di trend laterale. Puoi trovare delle spiegazioni dettagliate di questi trend nei nostri video.
Il grafico seguente mostra due trend molto diversi relativi a due siti web tedeschi rimasti stabili nell’arco di un lungo periodo di tempo. In rosso abbiamo un trend al rialzo del dominio apotheken-umschau.de e, in blu, il trend al ribasso del dominio netdoktor.de.
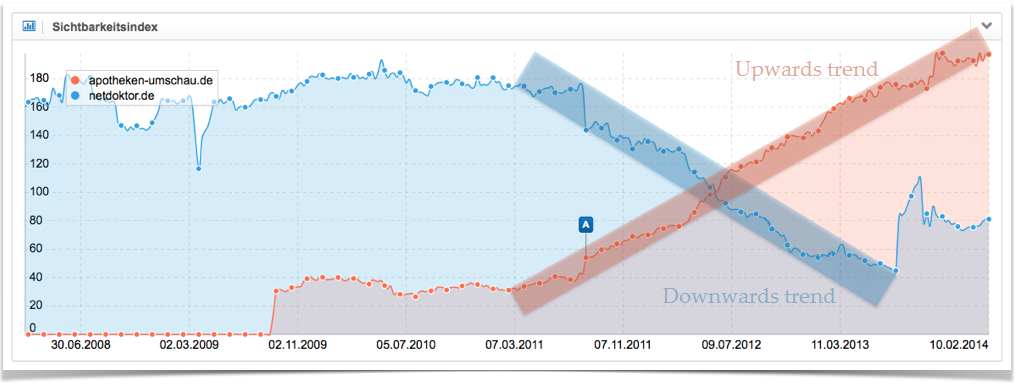
Il modello dell’“ottimizzazione dello spazio sullo scaffale” che abbiamo introdotto si adatterebbe molto bene a spiegare questi trend. Un dominio con dei valori di Searcher Satisfaction più alti della media guadagna sempre più visibilità, un passo alla volta. È possibile utilizzare in modo più deciso il vincolo delle “impressioni SERP”. Questo trend continuerà nello stesso modo finché le impressioni del dominio all’interno dei risultati di ricerca non si ridurranno, cosa che porterà i valori di Searcher Satisfaction del dominio a scendere fino alla quota media.
Se un dominio genera dei valori sotto la media, perderà visibilità e sarà in grado di utilizzare il vincolo in minor misura.
Ovviamente, ci sono anche altri fattori che influenzano la visibilità di un dominio: lo sviluppo dei link, la creazione di contenuti, l’ottimizzazione progressiva della SEO, i rinnovi della grafica del sito, gli aggiornamenti di Google e molto altro ancora.
Come si traduce tutto questo nella vita reale?
Saremo sinceri: questo modello di “ottimizzazione dello spazio su scaffale” di Google è un semplice costrutto teorico che non è mai stato sperimentato. Tuttavia, per comprendere meglio certi processi è utile immaginarsi un modello funzionante dell’algoritmo di Google. Se pensi che sia un modello fattibile, allora significa che abbiamo a disposizione due leve principali da poter sfruttare nel mondo reale.
- Ottimizzazione della performance: Tutte le misure di successo atte ad aumentare la Searcher Satisfaction di un dominio specifico aumenteranno la visibilità del dominio attraverso un miglioramento dei ranking.
- Ottimizzare la rivendicazione del vincolo: Ogni sezione di contenuto indicizzata avente una Searcher Satisfaction sotto la media diminuirà la performance generale del dominio, riducendo, quindi, la visibilità di questo all’interno dei risultati di ricerca di Google. Questa è la ragione per cui sarebbe meglio non mostrare a Google le pagine poco “produttive” (usando
<meta name="robots" content="noindex">). Al fine di ottenere, in futuro, una fetta maggiore di rivendicazione del vincolo da parte di Google e per competere al vincolo di “impressioni”, dovresti cercare di possedere soltanto pagine con una buona performance.
Mentre all’ottimizzazione della performance vengono dedicati articoli e dibattiti, non sentiamo quasi mai parlare dell’ottimizzazione della rivendicazione del vincolo, che ha lo scopo, nello specifico, di decidere quali sezioni di contenuto è utile far indicizzare da Google e quali è meglio evitare. Molti esperti della SEO ti confermeranno il nostro punto di vista: al fine di migliorare enormemente i tuoi ranking sarebbe meglio avere, all’interno dell’indice, solo quelle pagine davvero utili e dai contenuti unici, escludendo quelle aventi un contenuto poco curato. Queste osservazioni vengono anche spiegate dal nostro modello di “ottimizzazione dello spazio su scaffale”.
9 consigli per ottimizzare la rivendicazione del vincolo nella vita reale
Infine, vorrei darti 9 consigli per ottimizzare la rivendicazione del vincolo per le “impressioni SERP”.
- Controlla regolarmente i dati del CTR all’interno di Google Search Console, in modo da venire a conoscenza dei punti di forza e di debolezza del tuo dominio.
- Una volta che conosci i tuoi punti di forza, crea più contenuti dello stesso tipo.
- Per le pagine e le query di ricerca con un basso CTR, cerca di capire se la pagina è ottimizzata per la query di ricerca appropriata. La tua pagina potrebbe infatti disporre di ottimi contenuti, ma essere mostrata per la query di ricerca scorretta a causa di segnali sbagliati. Dai un’occhiata ai primi 10 risultati (titolo, descrizione, URL) su Google per la keyword che t’interessa e cerca di capire se questi rispondono più adeguatamente alla query, mettendoti nella posizione di un utente che effettua una ricerca e dei suoi bisogni.
- Imposta come NoIndex le pagine con dati del CTR negativi e contenuti privi di un significativo valore aggiunto, per rafforzare il resto delle tue pagine.
- Sarebbe ancora meglio se riuscissi a identificare interi gruppi di pagine da impostare su NoIndex, in modo che non ti diano più problemi. Pensaci due volte: ti servono davvero, all’interno dell’indice, tutte quelle opzioni di filtro per il tuo negozio online? Il dominio zalando.co.uk, per esempio, permette a Google d’indicizzare le pagine filtrate “calzature business da uomo” e “calzature nere business da uomo”. Le pagine con i contenuti filtrati per “calzature in pelle nera business da uomo”, invece, sono impostate come NoIndex, perché questa caratteristica non è molto ricercata e si perderebbe la selettività degli altri due filtri. Facendo un altro esempio, avrebbe senso indicizzare una directory di Pagine Gialle formata da 3.500 categorie relative a piccoli centri abitati? Oppure le pagine con contenuti obsoleti, come gli annunci scaduti? È invece molto utile avere un separatore chiaro e tangibile nella tua strategia di indicizzazione, al fine di non indebolire il vincolo con contenuti di bassa qualità.
- Lo User Generated Content (UGC) è sicuramente un contenuto a basso prezzo, ma la sua qualità e il suo valore aggiunto lasciano piuttosto a desiderare. Questa è la ragione per cui i forum e i portali di domande e risposte creano dei segnali utenti alquanto negativi. Dovresti, qui, introdurre un sistema efficiente per assicurarti che vengano indicizzati solo i contenuti significativi. Questa selezione può essere effettuata da uno staff editoriale o da un sistema automatico di rating, per esempio, basato sul voto dato dagli stessi utenti.
- Non importa come Google definisca la Searcher Satisfaction, i valori del CTR ne fanno probabilmente parte. Puoi aumentare il CTR attraverso un design dei tuoi risultati che sia orientato verso questo obiettivo (titolo, descrizione, URL). Un risultato dovrebbe comunicare importanza e valore aggiunto, suggerendo una determinata azione (“call to action”). Infine, durante l’inserimento della meta description, tieni sempre a mente il principio AIDA.
- Tieni d’occhio il numero delle pagine indicizzate ed esamina le possibili ragioni che potrebbero aver causato dei grandi cambiamenti, così da poter prendere, se necessario, le giuste contromisure.
- Evita i contenuti duplicati.