
Se si usa il robots.txt per bloccare l’accesso al crawler di un motore di ricerca relativamente ad una cartella o una pagina specifica, il contenuto di tale pagina/cartella non verrà scansionato, né indicizzato.
Puoi impedire ai crawler la scansione di una cartella (nell’esempio “una-directory”) e di una pagina (“una-pagina.html”) usando la seguente aggiunta al file robots.txt:
User-agent: *
Disallow: /una-directory/
Disallow: /una-pagina.htmlPerché trovo la mia pagina nei risultati di ricerca anche se è bloccata tramite robots.txt?
In alcuni casi, Google mostrerà una pagina bloccata tramite robots.txt nelle SERP (pagine dei risultati di ricerca).
Tuttavia, il crawler rispetterà comunque il robots.txt e non inserirà il contenuto di tale pagina nel suo indice. Google, quindi, non disporrà di alcuna informazione sul suo contenuto.
In quali occasioni una pagina bloccata appare nelle SERP?
Se la pagina bloccata presenta numerosi link in entrata con un linktext ben chiaro, allora Google potrebbe considerare il contenuto della pagina rilevante e quindi mostrare l’URL corrispondente all’interno dei risultati di ricerca.
Il contenuto di quest’ultimo, tuttavia, rimarrà sconosciuto a Google, siccome il robots.txt gli vieterà la scansione e l’indicizzazione. Il risultato apparirà quindi con la dicitura “Nessuna informazione disponibile per questa pagina” e con un link verso la Guida di Search Console.
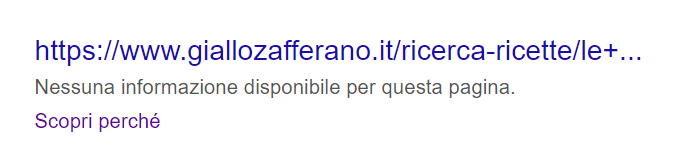
Solitamente è possibile riconoscere le pagine bloccate da robots.txt all’interno delle SERP proprio perché lo Snippet è incompleto (nel caso precedente, manca la description).
Google fa sempre più attenzione ai segnali degli utenti
Facciamo un esempio. Decidiamo di usare il robots.txt per bloccare l’accesso alla nostra pagina http://www.dominio.com/torta-della-nonna.html.
Il crawler di Google ubbidirà alla nostra richiesta e non scansionerà il contenuto della pagina, per cui non avrà idea del suo contenuto.
Ipotizziamo che questa pagina contenga una ricetta estremamente deliziosa e che ottenga quindi dei link da tantissimi altri siti, molti dei quali usando il linktext “La ricetta della nonna migliore del mondo”. In questo caso, la pagina bloccata http://www.dominio.com/torta-della-nonna.html potrebbe apparire nelle pagine dei risultati di ricerca per la query “Ricetta della nonna migliore del mondo”, anche se abbiamo bloccato il crawler tramite robots.txt.
Come impedire del tutto che un contenuto sia mostrato nelle pagine dei risultati di ricerca
Il file robots.txt non garantisce l’esclusione di una pagina dai risultati di ricerca.
Per essere certi che questo avvenga, dovrai usare il Meta-Element Robots con il valore NOINDEX.
Cosa dice Google?
Anche se non possiamo accedere ad un URL, possiamo sapere dagli Anchor Text (...) che linkano a questo URL che si tratta probabilmente di un risultato utile. Se non vuoi assolutamente che una pagina compaia (nelle pagine dei risultati di ricerca) usa il Tag NoIndex. In quel modo essa non apparirà sicuramente nelle pagine dei risultati.
Fonte: Matt Cutts